Street Fighter II - Reinforcement Learning Agent
Machine learning is typically divided into two categories; supervised and unsupervised learning, where algorithms learn from either labeled or unlabeled data. However, there are some problems that are more open-ended and don't fit into these categories. This is where reinforcement learning comes in. Reinforcement learning is able to solve problems in dynamic environments by using an agent to explore these environments, and using a reward to optimize its behavior. This approach has led to breakthroughs in chess bots, go bots, and self driving cars. In this post I will document my training and implementation of a reinforcement learning agent that can consistently beat players at Street Fighter II.
A Brief Explanation of Reinforcement Learning
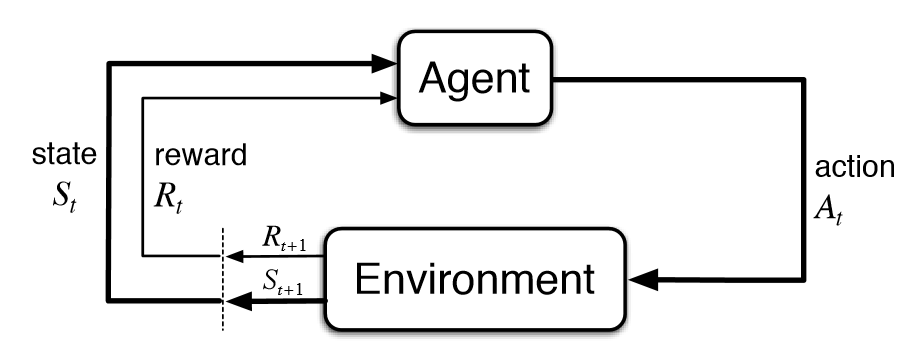
Reinforcement learning describes the method of updating a model's weights based on some reward system. The reinforcement learning algorithm consists of both an agent and environment. The agent takes action based on the input provided by the environment. In essence the agent is the neural network, the environment is the input, and the action is the output based on the input. Instead of using a loss function the weights are updated via a reward function.
Challenges Assosciated with Reinforcement Learning
There are some challenges attributed to reinforcement learning. One of which being the tendency for the agent to exploit the reward function, and learn unintended behaviors. As such it is incredibly important to design an environment and reward function that offer little room for bugs or exploits.
Another challenge, which is mostly addressed in choice of policy is learning stability. Reinforcement learning agents are extremely sensitive to environment and training parameters which can cause a model to overshoot and never converge.
PPO VS A2C
There are many different reinforcement learning algorithms, I will discuss the 2 most common, that being Proximal Policy Optimization (PPO) and Advantage Actor-Critic (A2C).
Proximal Policy Optimization (PPO)
PPO is a policy gradient method, meaning it uses the policies gradient to update the policy weights. This is similar to how a neural network trains via gradient descent. However, training this way can be unstable, to improve learning stability a constraint is added to clip the gradient change. This constraint ensures that the policy doesn’t change rapidly, artificially stabilizing it.
Advantage Actor-Critic (A2C)
A2C combines the advantages of both policy gradient methods and point based methods. A2C consists of an actor, which is a policy updated via policy gradient methods, and a critic, which judges the actors actions. When a new state is created by the environment the actor performs an action, the critic takes both the state and the action and calculates the difference between the expected reward (Q-Value) and the reward regardless of action (Average Value). This difference, known as the advantage, helps the critic guide the actor in optimizing its policy.
Challenges in Street Fighter Agents
Temporal Aspect
There are a few challenges attributed with making a Street Fighter specific agent capable of beating real players. Unlike other retro games, Street Fighter has a complex action space, specifically in the form of combos, where consecutive button presses result in different actions. For example, to pull off the infamous Haduken, the player must hit the ↓→a consecutively. These combos introduce a temporal aspect to the game which isn't represented by a single obvservation space.
Sequential Levels
Another issue that must be addressed is how the game is structured. In Street Fighter you can’t play the next level until you beat the level before it. This means our agent during training is constantly fighting the 1st and 2nd characters, and rarely getting the opportunity to train on the ones after.
Street Fighter II is structured in a sequence of levels, requiring the player to beat the current level before progressing to the next. This sequential format is detrimental to our reinforcement learning agent, as it limites the exposure to different environments, causing it to overfit. In the current format, our agent would train almost exlusively on the first 2-3 levels, overfitting to those few opponents .
Reward Exploitation
Further issues come from the 3 round system. In street fighter you win a level by winning 2 out of 3 rounds. In these rounds you gain points by landing hits and combos, these points are then used as our reward function by default. This creates a vulnerability that the agent can exploit by purposely losing the second round to maximize its total reward, resulting in a undesirable behavior that could cause our agent to lose in real trials.
Training
OpenAI has libraries that allow the implementation of reinforcement learning agents. The two main ones are the Baselines library which allows the implementation of agents, and the Gym library which allows the implementation of environments. For the purposes of this project I will be using a fork of the Baselines library called Stable Baselines which offers better implementation of the existing algorithms. For the environments, I will be using a fork of the Gym library called Retro-Gym. This is a fork with extended functionality that allows for the use and editing of retro games to create game states and environments.
At the time of writing this project I used a GTX 1060 for training, as a result I made an effort of keeping the model and observation space simple, whilst still attempting to solve the problems stated above.
Agent
I chose A2C, since it is less computationally expensive. I also keep the default network provided with A2C; a dense neural network with 4 layers, the input being the size of the observation space, the hidden layers consisting of 2 dense layers with 64 nodes each, and an output space of 12, matching the 12 actions that our agent can take each frame.
Observation Space
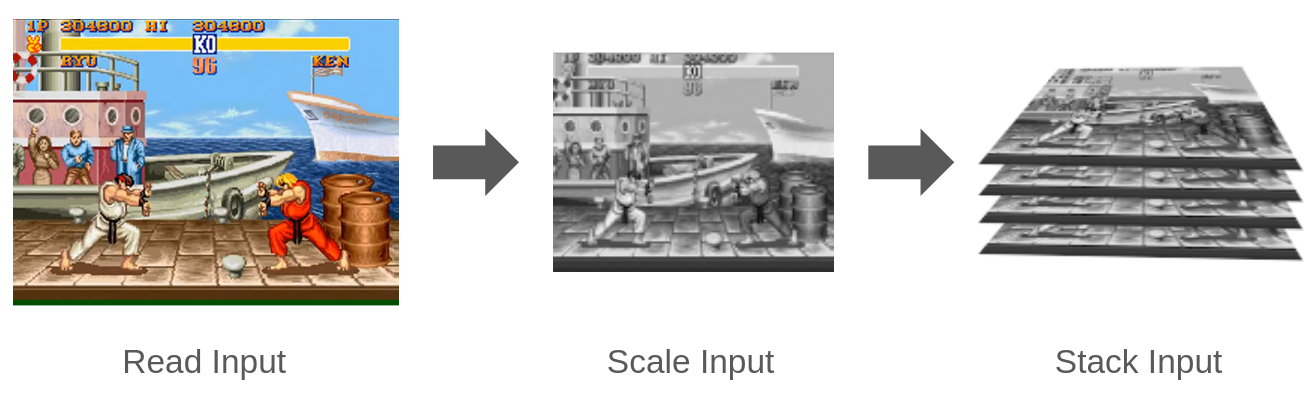
I downscale the resolution of the observation space to a shape of (128, 100, 1), this is large enough to make out necessary patterns but small enough to speed up training considerably. However, after training 2 separate agents, one using a CNN as input and the other using a dense layer as input, the dense network performed better. I believe this is because the observation space is too small to draw meaningful patterns using a CNN.
I currently have an observation space consisting of a single frame. To add a temporal aspect to the observation space, I store both the current frame as well as the previous 3 frames in a stack. I then pass the stack to the agent as the observation space. To achieve this I use the built-in VecFrameStack() object in stable baselines. This solves the lack of temporal input in our agent without needing to introduce computationally expensive LSTM or RNN layers.
Training Structure
To solve the issues with sequential levels and reward exploitation I need to change the constraints of the environment that our agent acts in. To do this I use the retro-gym tool that allows me to change these constraints. I start by creating a new game state for each level, changing the constraints to finish the game after our agent loses once. This allows our agent to still achieve a large reward for winning rounds consecutively but punishes it for losing on purpose, solving the reward exploitation. I then take these game states and add them to a list, our agent will train across each of these game states for 100,000 time steps. This boosts the agent's performance against real players significantly. Training the agent in a variety of environments prevents it from overfitting to the first 2 or 3 combatants, allowing it to generalize across all combatants.
Deployment
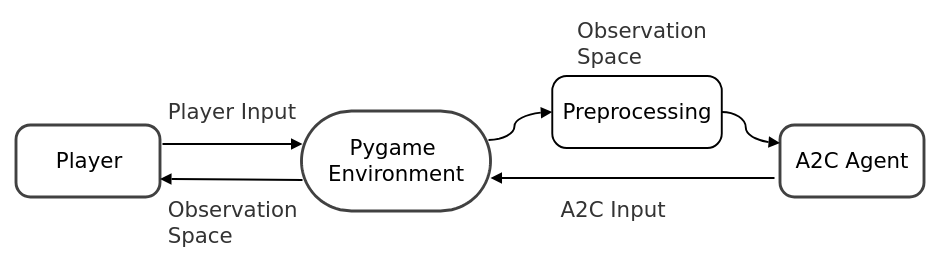
After training the model for 2,400,000 across all levels we have a model that can consistently win the game. However, we want to test this against players. To do this we use a popular python library PyGame. Pygame allows us to display the game to a window, as well as handling controller input.
The pipeline for this consists of 2 separate environments, the first environment allows both characters to be controlled by external outputs. The other environment is exactly the same as our training environment. We do this because our model wasn’t trained on a 2 player environment which has a larger action space, so we instead create an observation space in the 2 player environment and pass it to our model as if it was a single player observation space. We then take the output action space and concatenate it with our real players action space and pass this action space to the 2 player environment. This allows both a real world player, and an agent trained in a single player environment to act in the same environment.
Results
To test this I brought it to multiple student organization fairs at UTK to advertise for my machine learning club. Here we were able to get around 100 participants to compete against our street fighter agent, of which, only 2 were able to beat it. One of these 2 participants were a professional street fighter player, and the other was able to exploit a weakness after spamming a down kick.
Conclusion
This was actually my very first big machine learning project and was originally created to advertise for my university's machine learning club at engagement fairs. Given the complexity of Street Fighter 2, the simplicity of the model, and computational limitations, I am very happy with how this turned out.
That being said, if I were to do this project today with the skills and experience I have gained since finishing this project I would likely make a number of changes. One being to make use of ram values as opposed to just using a neural network to extract information at each frame, ram values can include information such as player health, states, and location. This would both provide much cleaner data for our agent to use, as well as decrease training time. However this would likely increase complexity when implementing the player vs agent scenario.
Overall this was a very exciting project that drew in a lot of engagement for our club, getting new college students interested in machine learning.
Thank you for reading.